Question List in November, 2020
🌨 Something we loved always leave us alone.
十品庄严净土。“是故须菩提!诸菩萨摩诃萨应如是生清净心,不应住色生心,不应住声香味触法生心,应无所住而生其心。须菩提!譬如有人,身如须弥山王,于意云何?是身为大不?”须菩提言:“甚大,世尊!何以故?佛说非身,是名大身。”Q1、PagedLOD优化
目前发现的问题以及待研究的内容有:
接下来就据此开展下一步研究和应用。据龙哥指示,本月的PagedLOD优化当舍弃原有的离散取值方案,而进一步采用精细DSM格网借助QSLIM库进行顶点精简的策略来执行下一步的优化操作。
QSlim
QSlim全称为Quadric-based Simplification Algorithm,是由Michael Garland于1999年所提出的一种基于边折叠简化算法的格网简化开源库。该算法库包含libgfx、MixKit、QSlim三个核心算法库以及QVis、SMFView两个图形可视化基础库,其基本介绍如下:
libgfx库和Qvis库都依赖于开源图形用户界面库FLTK,也即Fast Light Tool Kit,发音为/fulltick/。该库的编译并不复杂,唯一需要注意的是FLTK库的版本号为1.3.0,需要的各库的版本如下:
依赖库 版本号 编译方式FLTK 1.3.0 tools/fltk-1.3.0/ide/VisualC2010/fltk.slnlibjpeg 8d tools/jpeg-8d;jconfig.vc改成jconfig.h, 执行nmake -f makefile.vczlib 1.2.5 tools/zlib-1.2.5/contrib/vstudio/vc10/zlibvc.slnlibpng 1.4.11 tools/libpng-1.4.11/projects/vstudio/vstudio.slnlibtiff 4.0.3 tools/tiff-4.0.3;编辑nmake.opt, 执行nmake -f Makefile.vc
Hash
哈希算法是由Hans Peter Luhn所发明的,1958年11月,Luhn在科学信息国际会议上提出了一个借助上下文关键字索引来检索单词和句子的Key Word in Context,即KWIC算法。这种用于快速为文本信息建立索引的算法在当时引起了极大轰动,为了介绍这种算法能够做什么,我们先来谈谈它的先驱版本:针对数字所使用的存储桶方案。
1953年初,Luhn实现了一个IBM公司内部通讯录系统,该系统旨在将信息分发到桶中以提高检索效率。以在存储了一百万个10位数的电话号码的通讯录中查找电话号码314-159-2652为例,如果按位搜索号码,则最坏的情况下需要执行一千万次运算,这在那个年代的算力下可能会花费很长的时间。
Luhn提出的算法是,将10位数的电话号码两两分组并计算每组数字的和,取5组和的个位数按顺序组合成为一个新的数字。对于314-159-2652这一号码而言,将其两两分组可得到31、41、59、26、52这五组数,计算两个数字的和则结果为4、5、14、8、7,取个位数按顺序组合则得到标记数字45487,由此可将与电话号码314-159-2652相关的姓名、住址等相关信息放到45487这一桶中,通过分桶极大地提高了检索的效率。
以《乱世佳人》Gone With the Wind、《战争与和平》War and Peace、《风之影》The Shadow of the Wind和《战争之影》Shadows of War为例,用KWIC算法所建立的关键字索引应如下所示:

KWIC算法以所有可能的顺序重新排列标题中的关键词,然后按关键词首字母进行排序,最后输出包含关键字的完整上下文列表(包含除介词,连词和冠词以外的所有内容)。KWIC算法在文本索引方面的突出优势使其在科学界大放异彩,这种方法的原理与数字分桶相似,只不过它是以生成的文本关键字concordances来作为分桶的标识符的。KWIC算法已成为数字计算机时代的重要算法之一的Hash算法的先驱,目前看来,Hash函数之所以被命名为哈希与其理念提出者并无直接关联,这一方法的命名应当是以其单词语义为依托的,恰如其在中文译文中也常被翻译为散列。1958年的正当时,Luhn很快意识到该算法的巨大应用前景,并在《A Business Intelligence System》一文中提出了能够根据输入的文章自动生成改文章的摘要的方法,1964年的《纽约时报》中这样描述了他的方法:
“Mr. Luhn, in a demonstration, took a 2,326-word article on hormones of the nervous system from The Scientific American, inserted it in the form of magnetic tape into an I.B.M. computer, and pushed a button. Three minutes later, the machine’s automatic typewriter typed four sentences giving the gist of the article, of which the machine had made an abstract.”
MD–5
MD–5 即信息–摘要算法:Message–Digest Algorithm 5,是由R.Rivest于1992年所公开的用于确保信息传输完整一致的哈希函数,也是计算机广泛使用的杂凑算法之一。杂凑算法的基础原理是将数据运算为另一固定长度值,MD5 的前身有 MD2 、MD3 和 MD4 。MD5 是输入不定长度信息,经过程序流程,生成四个32位数据,最后联合起来成为一个 128–bits 散列的算法。其基本方式为:求余、取余、调整长度、与链接变量进行循环运算,得出结果,MD5 计算广泛应用于错误检查。
SHA–1
一号安全散列算法Secure Hash Algorithm–1是美国国家安全局1995年设计并交由美国国家标准技术研究所发布为联邦数据处理标准的一种哈希算法,也是哈希算法标准的先驱。SHA–1是一种密码散列函数,它可以可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常呈现为40个十六进制数。SHA–1曾在包括TLS、SSL、PGP、SSH、S/MIME和IPsec等安全协议中广为使用,也曾被视为是MD5的后继者。2017年,CWI Amsterdam与Google宣布了一个成功的SHA–1碰撞攻击,由此也为SHA家族的256号算法提供了发展的动力。
地形裙边
以osg::HeightField为例,这种地形重构方式提供了setSkirtHeight()函数。Skirt
Height俗称裙边,在汉语词典中有两种释义:
1.帽裙的边缘;2.鳖甲边缘的肉质部分。而在地形处理中,裙边指在生成地形时在每一个Tile四周围成一个栅栏并指定该栅栏的高度,以保证和相邻的Tile拼接时没有间隙。单个瓦片作为一个整体进行Mesh格网简化,然后对其添加地形裙边,避免地形接缝。
顶点索引重构
顶点索引重构算法的设计目的是为了在条带式osg::Geometry绘图节点的基础上,对图元几何的顶点坐标和面片索引进行重构以删除条带式几何中的重复顶点,从而实现一个标准的三维Mesh格网结构。
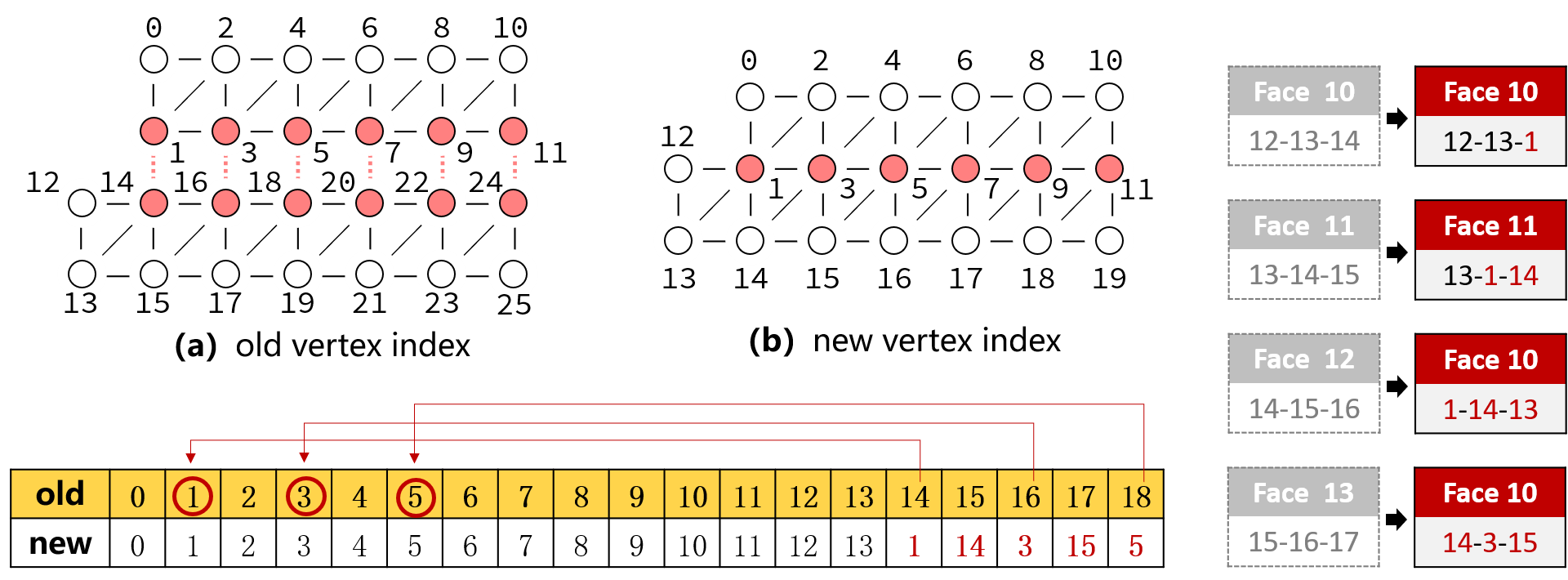
上图描述了条带式几何顶点转向标准 Mesh
顶点时的顶点索引重构过程。这一重构算法的核心在于确定重复顶点并在重复顶点处引用已创建了的顶点坐标的坐标索引。考虑到用float类型来相等来推断
osg::Vec3 类是否相等在精度方面可能存在的隐患,本文使用 MD5 算法对
osg::Vec3 顶点坐标字符求取散列值,并将该值作为 C++ 中map容器的
Key 值,由此来寻找重复的顶点。
由此设计的顶点坐标重构类VertexRestructor的主要成员变量及成员函数如下:
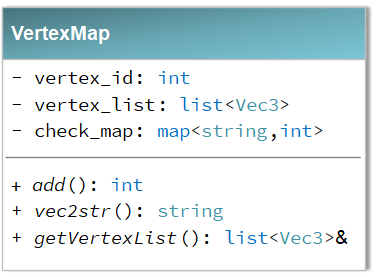
主要的实现函数为add()函数,vertex_id为自增索引变量,每次调用add()函数,则vertex_id会自增。所有的顶点坐标都存在链表vertex_list中,每次add()操作都会在check_map中检查是否含有重复的顶点坐标;如果该点已添加,则返回其原有索引;如果没有添加,则返回其新增索引。

参考文献
CSDN博客. Windows下的QSLIM编译和使用[EB/OL].
CSDN博客.zlib1.2.5 编译[EB/OL].
CSDN博客.模型简化[EB/OL].
CSDN博客.三维地形的调整和修饰[EB/OL].
Michael Garland.QSlim Simplification Software[EB/OL].
Michael Garland.QSlim 2.1[EB/OL].
Steven Skiena.The Stony Brook Algorithm Repository[EB/OL].
Michael Garland. Quadric-Based Polygonal Surface Simplification[J]. Computer Science Department, 1999: 99-105.
CMSC23700.Introduction to Computer Graphics[EB/OL].
Hallam Stevens.Hans Peter Luhn and the Birth of the Hashing Algorithm[EB/OL].
知乎.什么是哈希算法?[EB/OL].
我是小北挖哈哈.MD5的原理以及其实现过程[EB/OL].
百度百科.MD5[EB/OL].
刘巍然-学酥.如何评价2017年 2 月 23 日谷歌宣布实现了 SHA-1 碰撞?[EB/OL].
Q2、矢量拓展库osgShp的开发
适量导入模块为上月内容的接续,现将主要内容引用如下:
osgShp核心库的主要操作为为DotNetOsgApplication添加对矢量文件的支持,其旨在为OSG三维场景提供矢量格式图形的支持,目前需要研究的几个核心内容如下:
研习OSG中的osgSim::OvelayNode类,设计SHP文件的漂浮显示/贴地显示;
GDAL读取SHP并在OSG中绘制的相关方法,其被封装在OsgMfcLibrary\(\rightarrow\)ShpToIveTools中;
修改OsgProjectManager\(\rightarrow\)OsgProjectLoder中的代码以提供对SHP文件的支持;
用PropertyQueryManager工厂的方式来设计实现SHP相关的查询功能。
SHP文件的漂浮/贴地显示要与图层相关联,如若贴地显示则需要借用OverlayNode与底层实景模型图层节点进行绑定。关闭实景模型图层时,SHP文件会直接漂浮,再显示实景模型时,SHP不会贴地,把它关闭后重新打开。
目前已完成了基本内容的开发,接下来需要将矢量导入功能添加到Winform系统中。在osg::Node类下的setNodeMask()函数中,设置NodeMask为0时隐藏节点,设置为1时节点可见,即:
setNodeMask(0); //隐藏节点
setNodeMask(1); //显示节点
导入多个*.shp文件
继前面的研究,将 Subgraph 节点设定为 Group 节点以支持多个 SHP 文件。目前来看,实现多个 shp 文件的导入并不困难,实现贴地不贴地也不复杂。如下图所示,实黑色链接线和灰色连接线表示最开始导入 shp 时的情况,需要向 OverlayNode 中添加矢量时只需要将新创建的 Geometry 添加到 ShapeNode节点中;当需要对节点贴地情况进行变更时,只需要执行如虚红色链接线所指示的从 ShapeNode 节点中删除创建的节点并将该节点直接挂接到 OverlayNode 的子节点下即可。
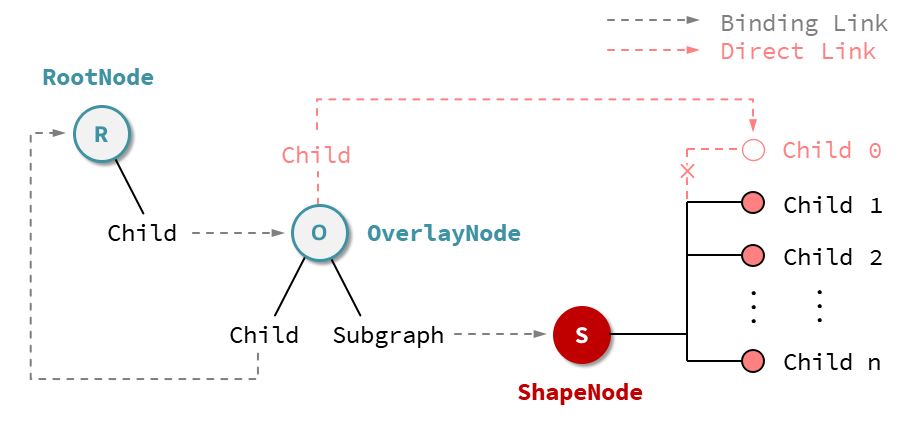
而目前存在的一个更为复杂的问题是,如何对工程应用中的模型节点加以控制。即,根据工程需要在软件中实现对某些节点的链接和操作以实现矢量文件在这些模型上的贴合。
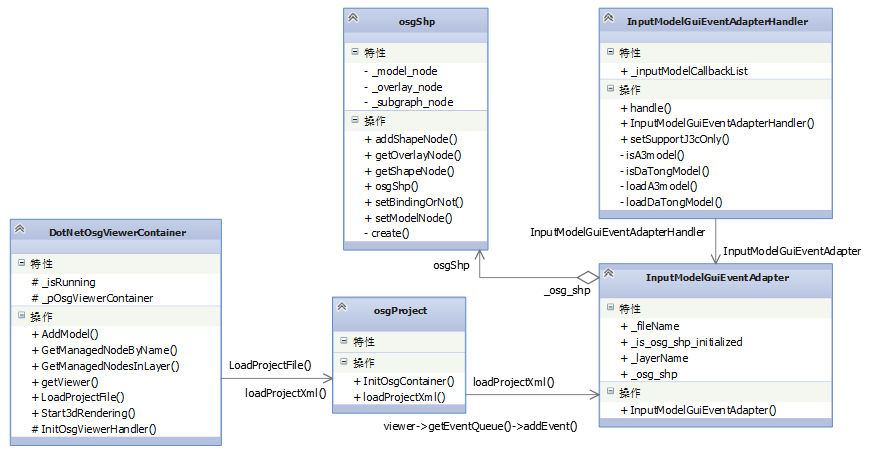
在 DotNetOsgApplication 中导入模型的函数调用以及类间关系如上图所示,模型导入的主体代码实现放在了操作类 InputModelEventAdapterHandler 中的 handle 函数中。
复杂面片绘制不正确
复杂面片的调整
参考文献
CSDN博客.C++函数指针[EB/OL].
博客园.VS20132015UML系列之类图[EB/OL].
Q3、C++ Tips
Debugs
error LNK2005
由于MixKit和QSlim库都是使用的静态编译,所以在将动态编译MD更改为静态编译MT时,MixKit经常会出现error LNK2005错误,即:
MSVCRT.lib(MSVCR120.dll) : error LNK2005: calloc 已经在 LIBCMT.lib(calloc.obj) 中定义。
其解决方案为:
右键点击项目\(\rightarrow\)属性\(\rightarrow\)连接器\(\rightarrow\)输入\(\rightarrow\)忽略特定默认库\(\rightarrow\)输入“libcmt.lib”
这里简单解释一下libcmt.lib和msvcrt.lib;libcmt.lib是Windows环境下VC提供的多线程静态运行时库;而与之相对的另一个库msvcrt.lib是动态运行时库。参考文献[15]对该部分内容作了详尽的解释。
MessageBox()
MessageBox指的是显示一个模态对话框,其中包含一个系统图标、 一组按钮和一个简短的特定于应用程序消息,如状态或错误的信息。消息框中返回一个整数值,该值指示用户单击了哪个按钮。其语法如下:
MessageBox(HWND hWnd, LPCTSTR lpText, LPCTSTR lpCaption, UINT uType);
其参数说明如下:
hWnd:
此参数代表消息框拥有的窗口。如果为NULL,则消息框没有拥有窗口。lpText: 消息框的内容。lpCaption: 消息框的标题。uType:
指定决定对话框的内容和行为的位标志集。此参数可以为下列标志组中标志的组合。指定下列C++的MessageBox()函数的示例代码如下所示:
MessageBox(
NULL,
"temp.txt already exists.\nDo you want to replace it?",
"Confirm Save As",
MB_ICONEXCLAMATION | MB_YESNO
);
函数指针
C++的函数指针就是指向函数的指针,与变量指针所不同的是其需要函数的相关参数。获取函数指针时,函数的地址就是函数名,要将函数作为参数进行传递,必须传递函数名;声明函数指针时,必须指定指针指向的数据类型,这意味着声明应当指定函数的返回类型以及函数的参数列表。
double (*sum)(int, int);void multiplication(int number, double (*sum)(int, int));这里还需要额外介绍C++的成员函数指针。当将函数指针用作C++类的成员变量时,其主要体现了C++语系的两个知识点:指针的声明以及赋值。其范例程序如下:
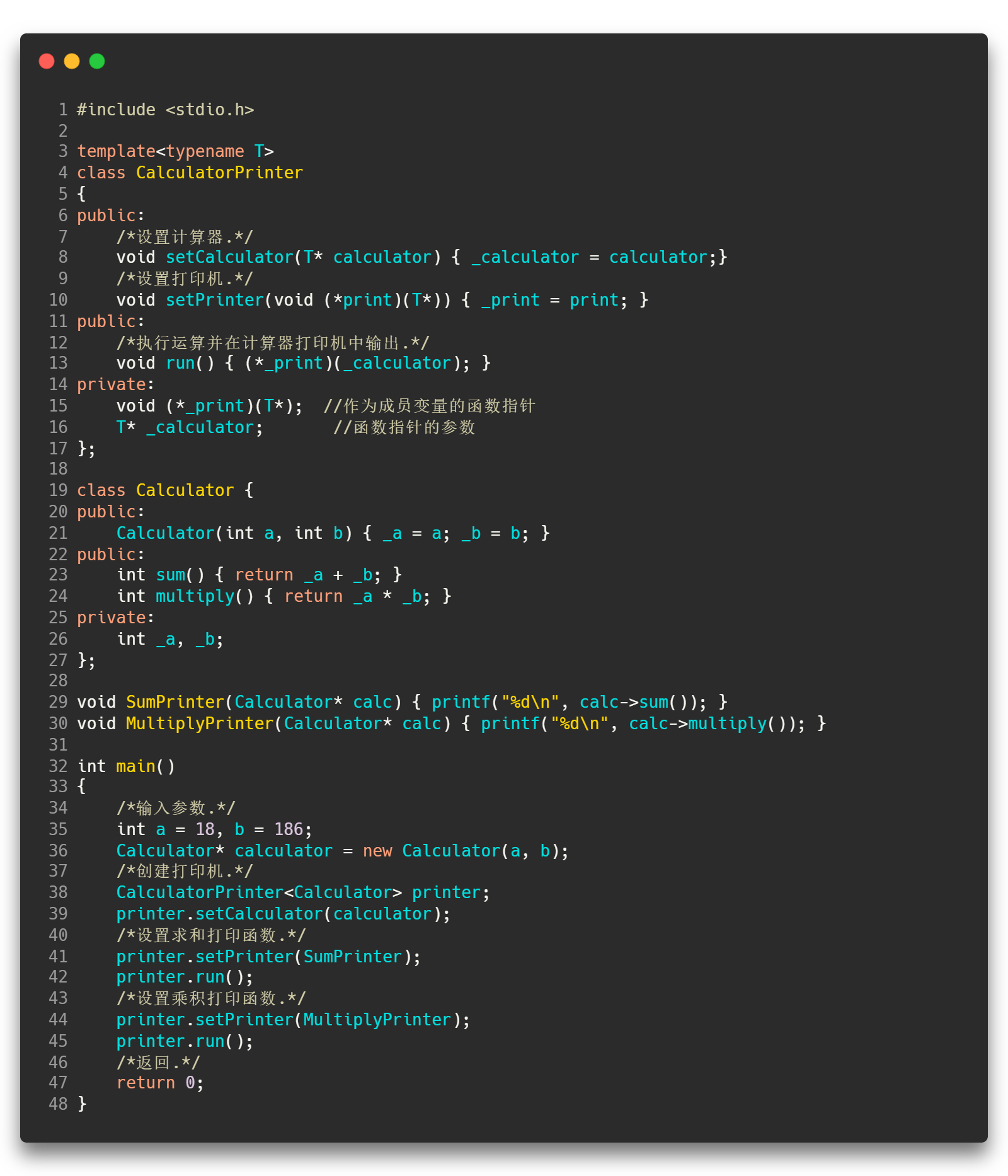
实现字符串的split()函数
在工程中使用了静态编译库QSlim,所以工程\(\rightarrow\)C++\(\rightarrow\)代码生成选项需要由“多线程/MD”切换成“多线程/MT”;这个变动引发了很多看起来莫名其妙的问题,其中就包括与basic_ostream相关的链接库错误。为了避免报错,在写代码时考虑用CRT(C Runtime)来取代iostream的功能,以免遭受这种烦恼。如将:
std::cout << "Hello World!" << std::endl; \(\rightarrow\)
printf("Hello World!\n");
这也是改写split()函数的初衷。另外,发现知乎博客中所设计的这个分割函数有点意思,抽时间研究一下:
void split(const string& s, vector<string>& tokens, const char& delim = ' ') {
tokens.clear();
size_t lastPos = s.find_first_not_of(delim, 0);
size_t pos = s.find(delim, lastPos);
while (lastPos != string::npos) {
tokens.emplace_back(s.substr(lastPos, pos - lastPos));
lastPos = s.find_first_not_of(delim, pos);
pos = s.find(delim, lastPos);
}
}
涉及到的几个函数如:printf、emplaceback、findfirstnotof、find等比较陌生。可以进一步分析一下其功能和使用方式。
关于float类型的NaN值
龙哥是真的流批,今天在做 DSM 插值时发现一个问题:对于自定义的作为 NoData 值的 -9999 做双三次插值时会在边缘处产生 -10000.0到900.0 的插值错误,这是因为在 GDAL 插值的过程中,将 -9999 作为有效数字参与到插值计算中去了。所以为了避免这一问题,需要使用 float 的 Not a Numbe r定义,即 NaN 非数来参与计算,在 C++ 标准库中定义了如下使用方式:
const float NaN = std::numeric_limits<float>::quiet_NaN();
NaN 值是 Not a Number 的缩写,在1985年的 IEEE754 浮点数标准中首次引入了对 NaN 的定义,用以表示无穷与非数值等一些特殊的数值。NaN 分为 Signaling NaN 与 Quiet NaN 两种,前者在使用时会在程序中发出无效操作的信号,而后者则能够执行几乎所有的算术运算而不作出无效操作警示。IEEE754 标准用指数部分全为1、小数部分非零表示NaN,即:
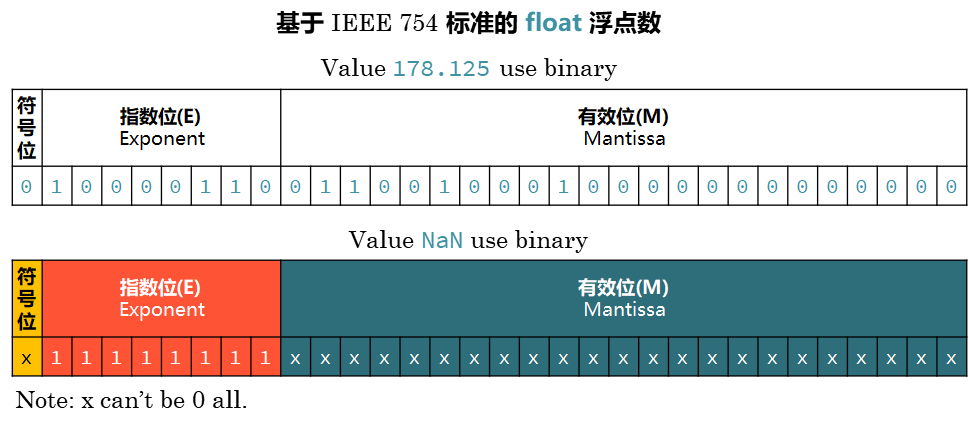
返回NaN的运算有如下三种:
至少有一个参数是NaN的运算;
- 不定式:某些除法运算:0/0、∞/∞、∞/(−∞)、(−∞)/∞、(−∞)/(−∞);某些乘法运算:0×∞、0×−∞;某些加法运算:∞ + (−∞)、(−∞) + ∞;某些减法运算:∞ - ∞、(−∞) - (−∞);某些指数运算:00、∞0、1∞、∞(−∞);
- 产生复数结果的实数运算,如:对负数进行开偶次方的运算;对负数(包含−∞)进行对数运算;对正弦或余弦值域以外的数进行反正弦或反余弦运算。
Proxy代理模式
osgDB下ObjectWrapper的BaseCompressor类使用了代理模式这样一种设计模式,私以为有点意思,所以在这里研究一下。该代理模式主要作用为,在Compressor.cpp文件中的BaseCompressor类的子类ZLibCompressor类委托ObjectWrapper.h文件中的RegisterCompressorProxy代理类,将其压缩功能注册到osgDB命名空间下的对象封装管理器ObjectWrapperManager类中,以此实现在保存文件时对文件的压缩。
这一设计的好处在于,新添加一种压缩模式时,无需修改ObjectWrapper.h文件,而只需在引用了该头文件的cpp文件中实现一个子类,并调用代理类将该子类注册到文件中去即可。不过这么分析下来,这种模式与代理模式有些出入,看功能目的似乎与适配器模式更贴近些。
游戏代练
代练的流程是,玩家 Client 把自己的账号交给代练人员 Proxy,让他们帮玩家操作人物施放技能赢得游戏,在这个过程中玩家只需要提供账号即可。代练人员要做的就是登陆玩家的账号然后替玩家打游戏;在玩家的朋友看来,是玩家的角色正在游戏,而无从知晓是不是你本人在打游戏,他只能看到你操作的英雄正在战斗,但并不需要知道实际打游戏的是谁。这就是代理模式,由他人代理玩游戏。
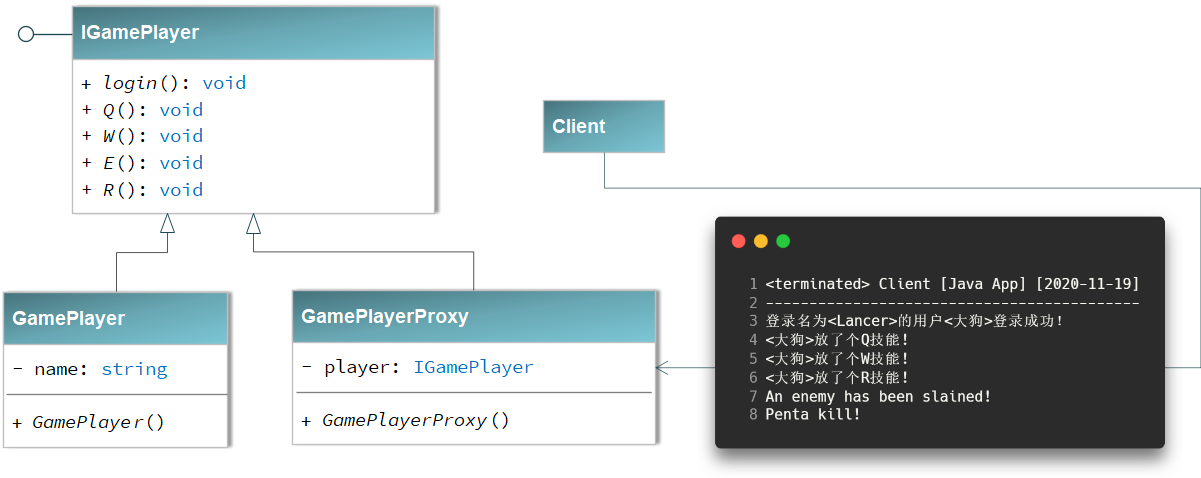
根据上面的思想,可以写出如下的代练代码:
public class Client {
public static void main(String[] args) {
IGamePlayer player = new GamePlayer("大狗");
IGamePlayer proxy = new GamePlayerProxy(player);
proxy.login("Lancer","CuChulainn");
proxy.Q();
proxy.W();
proxy.R();
}
}
文件压缩器
这里描述一下osgDB::writeNodeFile()函数的执行过程,在此过程中探索Options类是如何生效的,及其是如何实现在写入文件时执行zlib文件压缩的,其使用的类的UML结构图如下图所示:
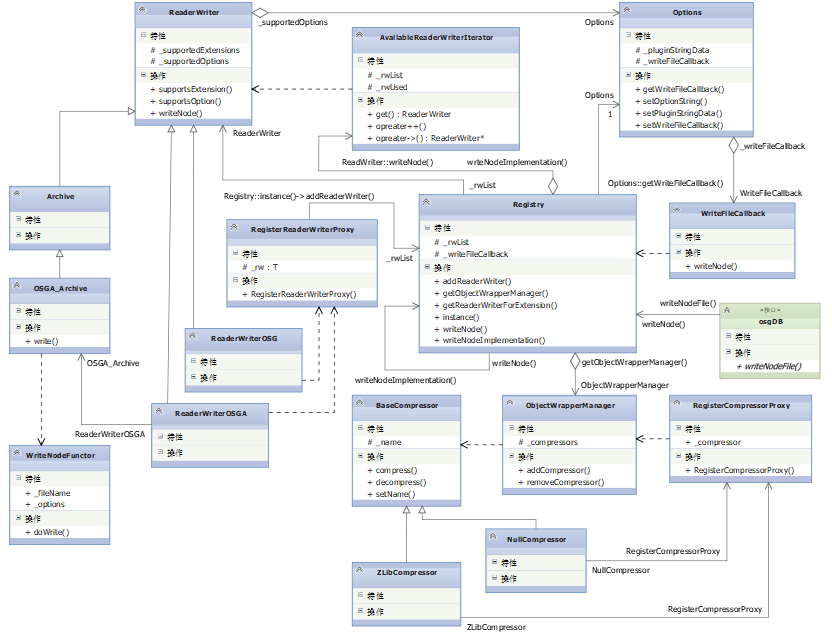
参考文献
知乎.C++实现字符串分割[EB/OL].
CSDN博客.终于理解了什么是c/c++运行时库,以及libcmt msvcrt等内容[EB/OL].
CSDN博客.C++中的消息框MessageBox()详细介绍及使用方法[EB/OL].
博客园.C++ MessageBox()[EB/OL].
CSDN博客.map,hashmap和unorderedmap效率比较[EB/OL].
博客园.fgets读取文件最后一行重复问题[EB/OL].
CSDN博客.C++中如何产生NAN数[EB/OL].
CSDN博客.IEEE浮点数表示–规格化/非规格化/无穷大/NaN[EB/OL].
CSDN博客.c中的inf和nan[EB/OL].
维基百科.NaN[EB/OL].
博客园.简说设计模式|代理模式[EB/OL].
Q4、图像缩放与插值算法
GDAL不仅支持最近邻插值、双线性插值、双三次插值等常见插值算法,其也提供了对Lanczos插值、Average插值、Mode插值以及高斯插值等其他插值方法。但GDAL从2.0版本才开始支持RasterIO接口进行插值算法配置,此前用RasterIO函数进行图像缩放时默认使用最近邻插值。
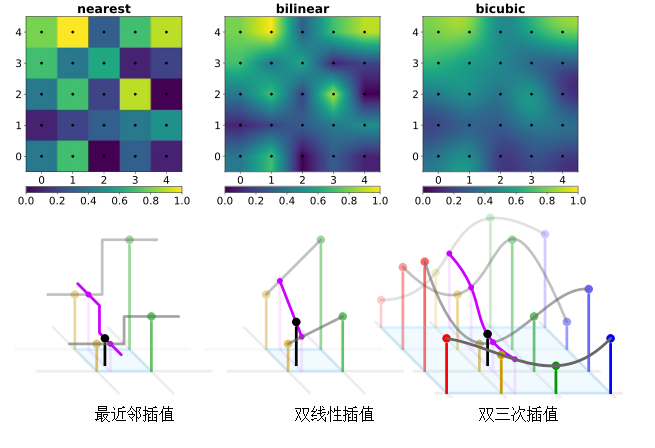
GDALRasterIOExtraArg exterArg;
INIT_RASTERIO_EXTRA_ARG(exterArg);
exterArg.eResampleAlg = GDALRIOResampleAlg::GRIORA_Bilinear;
RasterIO(···,&exterArg);
上回书说道,哦不是,我记错了,上回书说的是shape标准文件。*.tfw文件全称为 World File For TIFF,是GIS应用中存储 TIFF 图像数据的地理标签的一种明码文件,标准*.tfw文件共有6行,其含义如下:

其对应着GDAL的地理放射变换:
DSM偏移以及缝隙问题
GDAL读取GeoTIFF文件时,如果直接读取*.tfw文件的话,用GDAL进行缩放时可能会引起图像的偏移;这可能是在GDAL执行内部计算时所附加的一些不同的东西所引起的,用GDALDataset::GetGeoTransform()则可以解决这个问题。除此之外,还需要设定DSM图像和DOM图像的地理参考保持一致。
与此问题相关的问题还有利用DSM生成的模型的缝隙问题,该问题一般出现在构建顶层金字塔的过程中,暂时还没有想出症结所在,留待后续接着处理。
该问题已初步找到原由,即由图像像素分辨率过大所引起的边界模糊效应造成的边界缝隙现象,解决方案在下一章节中进行介绍,主要是设置恰当的模型金字塔因子。
色差问题
纹理与材质。身为三维人,怎么能老在纹理材质这块儿掉链子,我需要恶补一下纹理与材质这方面相关的内容;既然是以 OSG 为契机来学三维的,还是以和这个为样板来了解一些 OpenGL 中的纹理与材质的设置吧。这块问题在龙哥的指导下解决了,即将原始模型的*.osgb文件转化为*.osg文件,查看其渲染状态中的材质和纹理设置,并在生成模型时与之保持一致。
纹理 | Filter and Wrap
void glTexParameteri(GLenum target, GLenum pname, GLint param)
target:GL_TEXTURE_[1|2|3]D
A). 纹理过滤
当纹理贴到具体的像素上时,纹理中心不一定位置上刚好对应着像素坐标的中心,因此在贴图时会产生一定的偏差,会产生模糊错位等问题。这时我们就需要纹理的映射过程进行一定的处理时,这就是纹理过滤。在计算机图形学中,纹理过滤或者说纹理平滑是在纹理采样中使采样结果更加合理,以减少各种人为产生的穿帮现象的技术。纹理过滤分为放大过滤和缩小过滤两种类型。对应于这两种类型,纹理过滤可以是通过对稀疏纹理插值进行填充的重构过滤(需要放大)或者是需要的纹理尺寸低于纹理本身的尺寸时(需要缩小)的一种抗锯齿过滤。简单来讲,纹理过滤就是用来描述在不同形状、大小、角度和缩放比的情况下如何应用纹理。根据使用的过滤算法的不同,会得到不同等级的模糊、细节程度、空域锯齿、时域锯齿和块状结果。根据使用环境的不同,过滤可能是在软件或者专用硬件中完成,也可能是在软件和专用硬件中共同完成。对用大多数常见的可交互图形应用,现代的纹理过滤是使用专用的硬件进行完成。这些硬件通过内存缓冲和预提取技术优化了内存读写,并且实现了多种可供用户和开发者选择的过滤算法。
pname): GLTEXTUREMAGFILTER(纹理放大时),
GLTEXTUREMINFILTER(纹理缩小时);param):GLNEARST(最邻近的像素), GLLINEAR(线性插值);B). 纹理环绕
环绕方向(pname):GLTEXTUREWRAPS, GLTEXTUREWRAPT,
GLTEXTUREWRAPR //分别为xyz方向
参数(``param``):以下参数即为OpenGL的主要纹理环绕方式,REPEAR和CLAMP为两大类别:
GLREPEAT, GLMIRROREDREPEAT, GLCLAMP, GLCLAMPTOEDGE,
GLCLAMPTO_BORDER
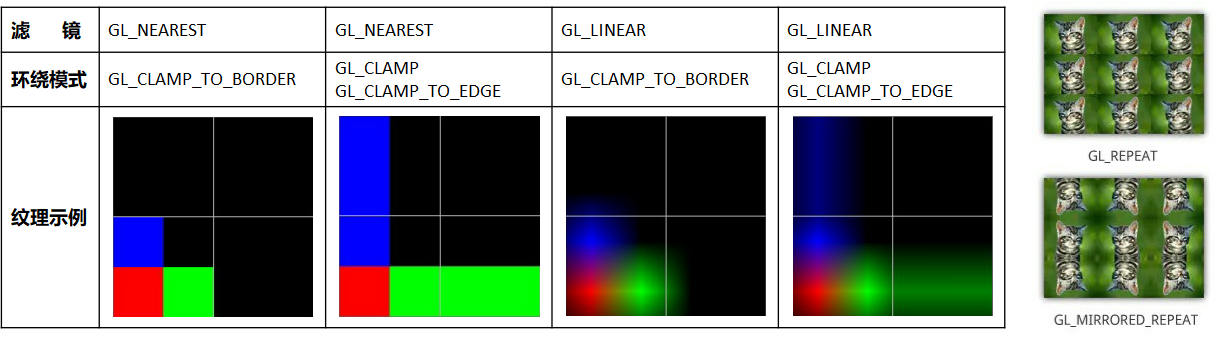
材质 | Material
OpenGL在处理光照时把光照系统分为三部分,分别是光源、材质和光照模型。光源、材质和光照模式都有各自的属性,尽管属性种类繁多,但这些属性都只用很少的几个函数来设置。材质主要由 Material Color 也即材质颜色来进行表达,其一般包括以下几点要素:
其中的ABC三点要素构成了冯氏(Phong Bui-Tuong)光照模型的基本参数,即:

人眼观察到的颜色,实际上是光照射物体后反射的光进入眼睛后感受到的颜色,其并不是物体实际的颜色。令\(C_r\) 为物体反射颜色,\(C_o\) 为物体颜色,\(I\) 为光照强度,则可将上述关系表述为:
一般将 Ambient 环境光照 \(I_a\) 表示为环境光系数常量 \(k_a=(R_a,G_a,B_a)\),即:
漫反射 Diffuse 光照度 \(I_d\) 表示为漫反射系数常量 \(k_d\) 与光线方向 \(\mathbf{l}\) 与法线方向 \(\mathbf{n}\) 的点乘结果的乘积,即:
镜面反射 Specular 的光照度 \(I_s\) 与镜面反射常量 \(k_s\),光线方向 \(\mathbf{l}\) 在物体表面反射时的反射光线 \(\mathbf{r}\),法线方向 \(\mathbf{n}\),观察方向 \(\mathbf{v}\) 以及反光度系数 \(k_{\mathrm{shininess}}\) 相关,即:
则由公式 1,2,3 最终生成的冯氏光照颜色为:
光照 | Lighting
光照一般分为点光源和平行光源,且光源在传播过程中会存在衰减现象。在本文生成DSM的过程中应保持生成的DSM要关闭光照,并使用快捷键[L]将模型亮度调整为最亮,以此确保生成的模型和原始模型之间不会存在太大的色差问题。关于这一部分内容暂且按下不表,因为目前的项目安排中还没有涉及到具体的关于光照的详细设计,在OSG会议上倒是有相关公司展开了这一方面的详细研究,名为基于物理的光照(PBR)的设计,这种方式的光照比之冯氏光照在渲染显示的效果方面还是有很大的提高的。其研究成果如下所示:

模型纹理波动
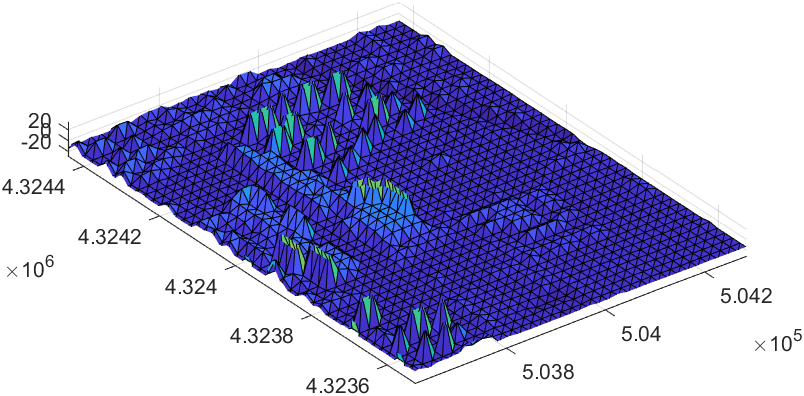
如下,在视角发生变化时,建筑物表面的纹理呈现一种均匀的条纹式变换。这种特殊的纹理效果有一个名词可以形容,叫啥来着我给忘了,好像是因为纹理网格太过密集引起的一种视觉现象。
缩放后的模型金字塔因子
令\(S_{DSM}\)为DSM影像的缩放因子,\(S_{DOM}\)为DOM影像的缩放因子,\(f_d\)为DSM影像离散取值参数,\(f_q\)为QSlim库对顶点简化的简化因子;取顶点简化率为\(F_{\mathrm{v}}\),纹理简化率为\(F_{\mathrm{t}}\),则最终生成的模型的简化率\(V\)为:
目前采用的方案是,根据影像分辨率从金字塔因子字典中取出默认简化率\(V_0\)作为计算基准,在随后的计算中根据金字塔的层级数量 \(l\) 对简化率 \(V_0\) 进行递减步处理。为降低锯齿效应,一般取 \(f_d=1.0\),则 \(F_{\mathrm{v}}=S_{DSM}\cdot f_q\),令四叉树层级集合为 \(\mathbb{L}=\{i\mid0\leqslant i<l,i\in\mathbb{N}\}\),由此可确定\(F_{\mathrm{v}}\)因子与层级\(i\)之间的关系:
比如对一个层级数量 \(l=7\) 的瓦片金字塔,其层级集合为 \(\mathbb{L}=\{0,1,2,3,4,5,6\}\);其中 \(L_0\) 为最底层瓦片,保持其瓦片的原有大小而不应计入当前计算。考虑到图像太小可能诱发的问题,\(S_{DSM}\) 不能下降的太厉害,需要用\(f_{q}\) 为其分担一部分下降因子,暂考虑:
同样地,也需要对纹理压缩因子进行相应的处理,可以考虑使用余弦函数的形式:
或反比例函数的形式:
取 \(l=4\) 时用Matlab对上述函数绘制,可得到如下图所示的函数图像。红色曲线为幂函数曲线,蓝色曲线为余弦函数与幂函数的叠加函数,绿色曲线为反比例函数。红色曲线取幂函数底数为 \(1/4\) 的目的在于,令实景模型金字塔向上采样时尽可能使采样后的大范围区域内的顶点数,与其下一级四分区域中的每一区域内的顶点数趋于一致。
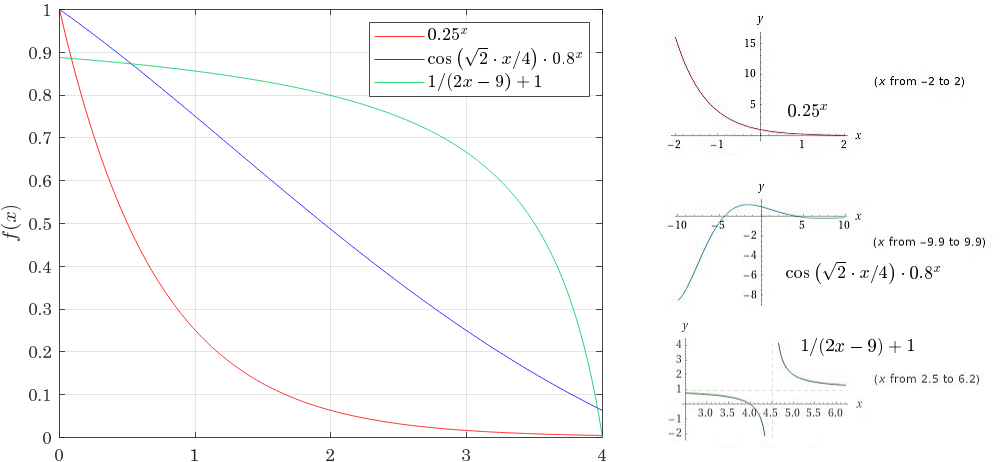
这里还需注意, 红色曲线所定义的曲线因子需要反馈于公式 \(F_{\mathrm{v}}=S_{DSM}\cdot f_q\) 所代表的参数中;若令四叉树层级集合中的第 \(i\) 层的顶点简化因子为 \(F_{\mathrm{v}i}=S_{DSM0}\cdot f_{qi}=(a\cdot S_{DSM0})\cdot(b\cdot f_{q0})\),则 \(a,b\) 应满足如下关系:
该关系可由公式 \((a\cdot b)^x=a^x\cdot b^x\)推导得到;在应用中,应该让DSM简化因子 \(S_{DSM}\) 下降的稍平缓些以免造成由图像像素分辨率过大所引起的边界模糊效应造成的边界缝隙现象;本文取\(a=3/4,b=1/3\)。
PLOD的RangeList配置
令四叉树层级集合为 \(\mathbb{L}=\{i\mid 0\leqslant i<l,i\in\mathbb{N}\}\),取其对应的 RangeList 链表为 \(\mathbb{R}=\{{r_i\mid i\in\mathbb{L}}\}\),当前能够明确已知的是单个瓦片的平面圆的半径 \(t\),取单个瓦片直径 \(d=2t\) 作为 RangeList 链表的计算单元,则有:
抽取四叉树集合中的几个层级到集合 \(\mathbb{S}=\{s_j\mid j\in\mathbb{N}\}\subset{\mathbb{L}}\) 中;当 \(j=0\) 时,建模时对最底层瓦片进行四叉树关联,此时取出 RangeList 中的对应元素 \(r_j\) 则应对其执行放大处理以满足 PLOD 缓存需求:
以上参数为暂定值,后续应根据分析对应调整并整理为合适的因子。分析了以上函数的特性后发现,如果目标层级过多,那么建立模型时,瓦片距离将几何倍增,不太符合我们的设计原则,所以还得进行下一步测试;目前测试的几个函数有:
考虑函数特性,\(f_3\) 函数的几何特征更符合我们的要求。另外,考虑到最顶层几级的 RangeList 的设置与纹理压缩因子密切相关,纹理压缩的越厉害,模型也应该离得越远,所以设定了这样一种调整因子 \(f_r\):
式中的 0.18 为经验值,只知道大概好像效果还可以,但为啥可以就不清楚了,可能并不通用,还需随时思考并加以调整。这个因子,随着 \(F_\mathrm{t}\) 的减小放大的太厉害了,应该考虑一个下降更为平缓的因子。目前的考虑是,当纹理缩放因子刚开始小于 0.1 时,取该因子 \(f_{r_0}=0.18/F_\mathrm{t}\),随后的因子采用:
的形式来执行计算。考虑上式的形式,与 RangeList 有所关联,计算结果应能满足一般需要。
参考文献
GDAL.RFC 51:RasterIO() 改进:重新采样和进度回调[EB/OL].
博客园.GDAL读取影像并插值[EB/OL].
博客园.图像插值算法总结[EB/OL].
CSDN博客.几种插值算法对比研究[EB/OL].
CSDN博客.OpenGL学习笔记(一)纹理基础知识[EB/OL].
CSDN博客.OSG新建图形并且添加上材质纹理和透明度[EB/OL].
CSDN博客.OSG中的材质Material[EB/OL].
博客园.Texture::setUnRefImageDataAfterApply[EB/OL].
博客园.OSG中的DataVariance[EB/OL].
osgChina|OpenSceneGraph Compressor=zlib.序列化支持[EB/OL].
zhxmdefj.OpenGL光照2:材质和光照贴图[EB/OL].
learnopenglcn.欢迎来到OpenGL的世界[EB/OL].
CSDN博客.OpenGL4种光照模型[EB/OL].
CSDN博客.OpenGL学习脚印: 光照基础[EB/OL].
Bui Tuong Phong. Illumination for Computer Generated Pictures[J]. Communications of the Acm, 1998, 18(6).